

环形缓冲区是一种在数据通信和计算机系统中常用的技术,它主要用于解决数据传输和处理的效率问题。通过使用环形缓冲区,可以实现对数据的快速读取和写入,避免了频繁的数据拷贝和内存分配,从而提高了系统的性能。环形缓冲区也可以实现对数据的批量处理,减少了每次处理数据时的开销,进一步提高了系统的效率。环形缓冲区还可以解决数据同步和并发访问的问题,保证数据的准确性和一致性。环形缓冲区在数据通信和计算机系统中得到了广泛的应用。
在计算机科学中,环形缓冲区(也称为循环缓冲区或C++中的std::queue)是一种线性数据结构,它使用固定大小的数组来存储数据,并通过两个指针(通常称为"头"和"尾")来跟踪数组的当前状态,这种结构允许我们在不浪费空间的情况下,高效地添加和删除数据。
环形缓冲区的优势
1、空间效率:环形缓冲区使用固定大小的数组来存储数据,这意味着它不需要额外的空间来存储指针或其他元数据,这使其在空间上非常高效,特别是在处理大量数据时。
2、时间效率:通过跟踪"头"和"尾"指针,我们可以在常数时间内完成数据的添加和删除操作,这种时间效率使得环形缓冲区在处理实时数据或需要高性能的场景中表现出色。
3、简单实现:环形缓冲区的实现相对简单,不需要复杂的链表操作或动态内存分配,这使得它成为教学和初学者项目的理想选择。
4、适用性广:环形缓冲区适用于多种场景,包括消息队列、事件处理、图像处理等,其广泛的应用范围使其成为一种非常实用的数据结构。

环形缓冲区的应用场景
1、消息队列:在分布式系统中,消息队列用于在不同的服务或组件之间传递消息,环形缓冲区可以用作消息队列的实现,确保消息的可靠传递并处理并发问题。
2、事件处理:在事件驱动的应用程序中,事件队列用于存储和处理大量事件,环形缓冲区可以提供高效的事件处理能力,确保系统的响应性和稳定性。
3、图像处理:在图像处理中,环形缓冲区可以用于存储图像数据或处理过程中的中间结果,其高效的空间和时间效率使得环形缓冲区成为图像处理算法的理想选择。
如何实现环形缓冲区
实现环形缓冲区通常需要以下几个步骤:
1、定义数组:我们需要定义一个固定大小的数组来存储数据,这个数组的大小可以根据实际需求进行选择。
2、初始化指针:我们需要初始化两个指针,"头"和"尾",分别指向数组的起始位置和结束位置,头指针指向数组的第一个元素,尾指针指向数组的最后一个元素。
3、添加数据:当有新数据需要添加时,我们将数据存储在尾指针所指向的位置,并将尾指针向前移动一位,如果尾指针到达数组的开头,我们需要将其重置到数组的末尾。
4、删除数据:当需要删除数据时,我们从头指针所指向的位置删除数据,并将头指针向后移动一位,如果头指针到达数组的末尾,我们需要将其重置到数组的开头。
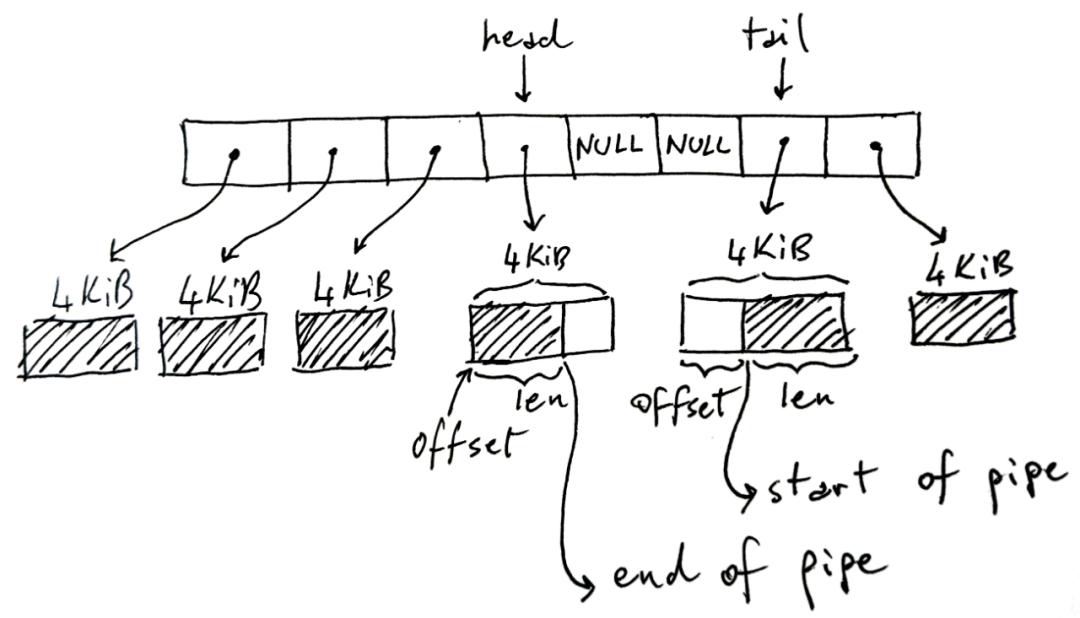
5、处理溢出:如果环形缓冲区已满,我们需要处理溢出问题,一种常见的策略是丢弃最早添加的数据,或者触发警报并停止添加新数据。
环形缓冲区是一种高效、简单且广泛应用的数据结构,它使用固定大小的数组来存储数据,并通过两个指针来跟踪数组的当前状态,环形缓冲区的优势在于其空间和时间效率都非常高,适用于多种场景,包括消息队列、事件处理和图像处理等,通过遵循几个基本步骤,我们可以轻松地实现环形缓冲区并在应用程序中使用它。
 沪ICP备16041027号
沪ICP备16041027号